 题图还是来自于网络
题图还是来自于网络
紧接「上篇」,我认为虽然在 SQL 语句方面已经入门、有开箱即用的水平了,但对数据库相关知识的理解还是半瓶水的状态,所以我找了一本日本人 MICK 写的《SQL 基础教程》,想作进一步的学习。本书中所有的例程均以 ISO 制定的标准语法 SQL:2011 展现,虽然这最初出版于 2011 年,已经有些老了,但入门嘛,老一点也没关系,先学好基础,再徐徐图之。
另外,在豆瓣的界面下,我看到有评论推荐了一个练习平台 sqlzoo。我凭借脑子里新鲜的数据库知识看了一下,感觉是十分合适的,正好能为我补上更多的「习题」部分。
那就让我们开始新的学习吧。
SQL 中的常数
SQL 语句中出现的常数一般是三种:字符串、数字和日期。其中字符串和日期均需要用单引号括起来,而数字可以直接书写,如:'abc'、'2022-10-18' 和 123。
表格创建、删除与更新
根据书上的例子,我们以这张表为后续的 SQL 语句示例:
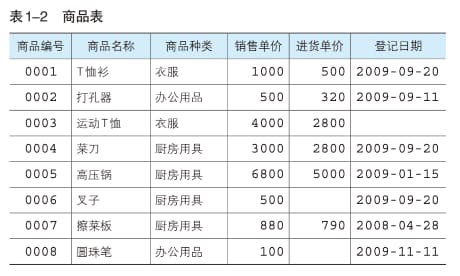
创建数据库 CREAT DATABASE
-- 创建一张名为 shop 的数据库
CREAT DATABASE shop创建表 CREAT TABLE
表的创建语法如下,我个人认为它更像是一种函数:

CREAT TABLE Product
(
product_id CHAR(4) NOT NULL, -- CHAR 定长字符类型
product_name VARCHAR(100) NOT NULL, -- VARCHAR 可变长度类型
product_type VARCHAR(32) NOT NULL, -- NULL 约束关键字
sale_price INTEGER , -- INTEGER 整数类型,不能有小数
purchase_price INTEGER ,
regist_date DATE , -- DATE 日期类型
PRIMARY KEY (product_id) -- 主键
);其中:NULL 是约束的关键字,NOT NULL 约束了以上三列的单元格必须填写,不能置空。最后一行的语句 PRIMARY KEY() 的参数是设置表的主键约束:
键:指定特定数据时的列集合;
主键:可以特定一行数据的列(即通过该列,任意行均能被唯一确定)。
删除表 DROP TABLE
-- 删除名为 Product 的表
DROP TABLE Product注意:删除的表是无法恢复的,只能重新创建新表,所以执行该操作之前务必小心。
更新表的定义 ALTER TABLE
为表添加某列时,可使用该语句:
ALTER TABLE <表名> ADD COLUMN <列名>
-- 注:不同的 SQL 语法可能会有不同的表述,在这里我们只关注 SQL:2011 与 MySQL
-- 例如:添加一列表示商品的拼音,存储 100 位的可变字符串
ALTER TABLE Product ADD COLUMN Product_name_pinyin VARCHAR(100);而删除表中的某列类似,改 ADD 为 DROP 即可:
ALTER TABLE <表名> DROP COLUMN <列名>
-- 例如:删去拼音名的列
ALTER TABLE Product DROP COLUMN Product_name_pinyin与 DROP TABLE 同理,列在删除后也无法恢复。
插入数据 INSERT INTO
在上一篇的学习笔记中,我们学到过 INSERT INTO () VALUES (),现在可以尝试一次性插入整张表:
# DML:插入数据
START TRANSACTION;
INSERT INTO Product VALUES ('0001', 'T恤衫', '衣服', 1000, 500, '2009-09-20');
INSERT INTO Product VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');
INSERT INTO Product VALUES ('0003', '运动T恤', '衣服', 4000, 2800, NULL);
INSERT INTO Product VALUES ('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
INSERT INTO Product VALUES ('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');
INSERT INTO Product VALUES ('0006', '叉子', '厨房用具', 500, NULL, '2009-09-20');
INSERT INTO Product VALUES ('0007', '擦菜板', '厨房用具', 880, 790, '2008-04-28');
INSERT INTO Product VALUES ('0008', '圆珠笔', '办公用品', 100, NULL,'2009-11-11');
COMMIT; -- COMMIT 为确定插入行的指令语句 数据库的基本查询
本节的内容是 SELECT 语句及算数、比较和逻辑运算符的基本使用方法。
查询列 SELECT
-- 基本查询
SELECT <列名>,……
FROM <表名>;
-- 如:输出三列
SELECT product_id, product_name, purchase_price
FROM Product;SELECT 语句后可跟多列,其间用逗号分隔。
-- 查询所有列
SELECT *
FROM <表名>;其中星号「*」代表全部列、全选的意思。
别名关键字 AS
在 SQL 语句中可使用 AS 为列设置别名:
-- 在各列名后使用 AS
SELECT product_id AS id,
product_name AS name,
purchase_price AS price
FROM Product;这样输出结果的时候就会用别名显示了。注意:当字符作为别名的时候,需要使用双引号括起来,这一点需要与前面的字符串常数相区别。
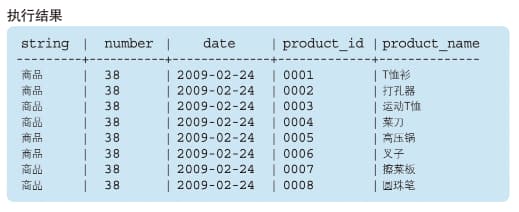
查询常数
这是一种查询表中特定常数的方法:
-- 输入:
SELECT '商品' AS string, 38 AS number, '2009-02-24' AS date,
product_id, product_name
FROM Product;输出如下:
去重关键字 DISTINCT
想要在输出的时候不显示重复行,可加入 DISTINCT 实现:
-- 单列:
SELECT DISTINCT product_type
FROM Product;
-- 多列:
SELECT DISTINCT product_type, regist_date
FROM Product;注意:NULL 也会被视为一类数据;DISTINCT 关键字只能位于第一个列名之前。
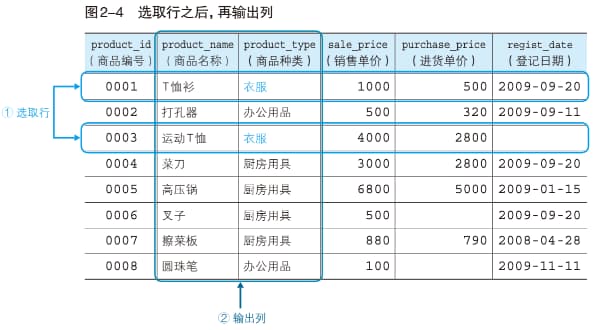
条件关键字 WHERE
可以使用 WHERE 关键字限定输出数据的条件:
SELECT <列名>, ……
FROM <表名>
WHERE <条件表达式>;
-- 如:
SELECT product_name, product_type
FROM Product
WHERE product_type = '衣服';关键字的执行顺序是先找到 WHERE 语句限定的行,再输出 SELECT 语句选定的列:
算数运算符
即加减乘除,括号会改变算式的优先级。
/*
加法:+
减法:-
乘法:*
除法:/
*/
-- SQL 语句中可以使用运算表达式,例如:
SELECT product_name, sale_price,
sale_price * 2 AS "sale_price_x2"
FROM Product;注意:所有包含 NULL 的运算,其结果均为 NULL。
比较运算符
/*
等于:=
不等于:<> 注意:此处是标准 SQL,有些数据库亦支持 !=;
大于:>
大于等于:>=
小于:<
小于等于:<=
*/可以对日期常数使用比较运算符:
-- 选取日期再 2009-09-27 之前的记录:
SELECT product_name, product_type, regist_date
FROM Product
WHERE regist_date < '2009-09-27';注意:对字符串使用不等号时,是依据字典顺序进行比较。(2 与 '2' 不一样,区分数字与字符串)
判断 NULL
希望以 NULL 元素选取记录时,应当用 IS NULL 或者 IS NOT NULL 运算符。
注意:不能对 NULL 使用比较运算符。
-- 错误示例:
SELECT product_name, purchase_price
FROM Product
WHERE purchase_price = NULL;
-- 正确示例:
SELECT product_name, purchase_price
FROM Product
WHERE purchase_price IS NULL;逻辑运算符
/*
非:NOT
与:AND
或:OR
*/比较运算符与逻辑运算符均会返回真值。
注意:AND 运算符的优先级高于 OR 运算符。
-- 例如,需要找办公用品,且日期在 11 号或者 20 号的记录:
SELECT product_name, product_type, regist_date
FROM Product
WHERE product_type = '办公用品'
AND regist_date = '2009-09-11'
OR regist_date = '2009-09-20';
-- 是不对的,这样的逻辑是先找「既是办公用品,又在 11 号」的记录,
-- 然后加上了所有「在 20 号」的记录
-- 也就是被解释为了:
-- (product_type = '办公用品' AND regist_date = '2009-09-11')
-- OR
-- (regist_date = '2009-09-20')
-- 所以现在应该用括号人为地限定优先级:
SELECT product_name, product_type, regist_date
FROM Product
WHERE product_type = '办公用品'
AND ( regist_date = '2009-09-11'
OR regist_date = '2009-09-20');三值逻辑(NULL 的真值)
SQL 语句中的真值有三种:TRUE、FALSE 和 UNKNOWN。当有 NULL 参与逻辑运算时,可能会出现 UNKNOWN。其真值表如下:
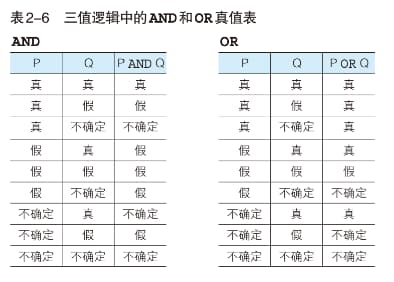
由于考虑 NULL 后,最初只有四行的真值表变成了现在的九行,所以在数据库中应该尽量不使用 NULL。
数据库的聚合查询
聚合:将多行汇聚为一行。
SQL 语句中有 5 个常用的函数:
COUNT:计算表中的记录数(行数)
SUM: 计算表中数 值列中数据的合计值
AVG: 计算表中数 值列中数据的平均值
MAX: 求出表中任意列中数据的最大值
MIN: 求出表中任意列中数据的最小值总数 COUNT
COUNT 函数能计算所有的数据行数,分两种情况:
-- 包括 NULL 数据的行数
SELECT COUNT(*)
FROM Product;
-- 不包括 NULL 数据的行数
SELECT COUNT(<列名>)
FROM Product;注意:只有 COUNT 函数中的参数可以为星号「*」,其他函数都不可以。
求和 SUM
SELECT SUM(<列名>)
FROM Product;注意:如果该列的单元格中含有 NULL,聚合函数会将 NULL 排除在外(不参与计算过程),但 COUNT(*) 是例外。
均值 AVG
SELECT AVG(<列名>)
FROM Product;例如计算含有 NULL 列的平均值时,由于 NULL 被排除在计算过程之外,所以其总数是减去了 NULL 项后,再参与的计算。
最大 MAX 与最小 MIN
SELECT MAX(<列名>)
FROM Product;
SELECT MIN(<列名>)
FROM Product;
-- 亦可计算日期的最大值、最小值:
SELECT MAX(regist_date), MIN(regist_date)
FROM Product;注意:MAX/MIN 函数几乎适用于所有数据类型的列。SUM/AVG 函数只适用于数值类型的列。
去重 DISTINCT
SELECT COUNT(DISTINCT <列名>)
FROM Product;这时 DISTINCT 必须写在括号中,因为这里有一个逻辑问题:现在是先删去重复的数据,再计算数据的行数;如果像之前一般,写在括号之外,那么就会先计算数据的行数,再删去重复的数据,结果仍为所有数据的行数。
-- 正确示例
SELECT COUNT(DISTINCT product_type)
FROM Product;
-- 此时返回的结果为 3
-- 错误示例
SELECT DISTINCT COUNT(product_type)
FROM Product;
-- 此时返回的结果为 8数据库的分组
聚合语句将表聚合为了一行,而使用 GROUP BY 分组语句,可以将表像切蛋糕那样分隔。
分组 GRUOP BY
SELECT <列名1>, <列名2>, <列名3>, ……
FROM <表名>
GROUP BY <列名1>, <列名2>, <列名3>, ……;
-- 例如,按照商品的种类统计行数:
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type;在 GROUP BY 子句中指定的列被称为聚合键。当聚合键中包含 NULL 时,在结果中会以「不确定」行(空行)的形式表现出来。
当使用聚合函数时,SELECT 子句中只能存在三种元素:常数、聚合函数和聚合键。
当 GROUP BY 与 WHERE 语句并用时,SQL 语句逻辑的执行顺序为:FROM → WHERE → GROUP BY → SELECT。
注意事项
- 使用
GROUP BY子句时,SELECT子句中不能出现聚合键之外的列名; - 在
GROUP BY子句中不能使用SELECT子句中定义的别名(因为语句逻辑顺序); GROUP BY并不参与对结果的排序,其显示的结果是随机的、无序的;- 只有
SELECT子句和HAVING子句(以及ORDER BY子句)中能够使用聚合函数。
指定条件 HAVING
SELECT <列名1>, <列名 2>, <列名 3>, ……
FROM <表名>
GROUP BY <列名1>, <列名2>, <列名3>, ……
HAVING <分组结果对应的条件>
-- 示例1:
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type
HAVING COUNT(*) = 2;
-- 示例2:
SELECT product_type, AVG(sale_price)
FROM Product
GROUP BY product_type
HAVING AVG(sale_price) >= 2500;- 在使用
COUNT函数等对表中数据进行汇总操作时,为其指定条件的不是WHERE子句,而是HAVING子句。WHERE子句只能指定记录(行)的条件,而不能用来指定组的条件。 - 聚合函数可以在
SELECT子句、HAVING子句和ORDER BY子句中使用。 HAVING子句要写在GROUP BY子句之后。WHERE子句用来指定数据行的条件,HAVING子句用来指定分组的条件。
同理,HAVING 语句中也只能使用三种要素:常数、聚合函数和聚合键。
排序 ORDER BY
SELECT <列名1>, <列名2>, <列名3>, ……
FROM <表名>
ORDER BY <排序基准列1>, <排序基准列2>, ……ORDER BY子句中的列名称为排序键;- 在
ORDER BY子句中列名的后面使用关键字ASC可以进行升序排序(默认,可不写),使用DESC关键字可以进行降序排序; - 在
ORDER BY子句中可以指定多个排序键;
-- 当第一个排序键的结果中出现相同值时,将根据右侧的排序键进行排序:
SELECT product_id, product_name, sale_price, purchase_price
FROM Product
ORDER BY sale_price, product_id;- 当排序健中包含 NULL 时,会在开头或末尾进行汇总;
- 在
ORDER BY子句中可以使用SELECT子句中定义的列的别名;
因为此时的语句逻辑顺序为:FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY。
- 在
ORDER BY子句中可以使用SELECT子句中未使用的列和聚合函数;
SELECT product_id AS id,
product_name,
sale_price AS sp,
purchase_price
FROM Product
ORDER BY sp, id;- 在
ORDER BY子句中不要使用列编号。
最后,以上语句的书写顺序为:1. SELECT 子句 → 2. FROM 子句 → 3. WHERE 子句 → 4. GROUP BY 子句 → 5. HAVING 子句 → 6. ORDER BY 子句。
数据库的更新
数据库的更新包括 INSERT、DELETE 和 UPDATE 三种修改表的指令,和进行相关操作的事务。
插入 INSERT
首先创建一个名为 productIns 的表作为示例,其中除了 sale_price 列设置了 DEFAULT 0 的约束外,其余内容与之前的 product 表完全相同。
-- 创建 ProductIns 表
CREATE TABLE ProductIns
(
product_id CHAR(4) NOT NULL,
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32) NOT NULL,
sale_price INTEGER DEFAULT 0,
purchase_price INTEGER ,
regist_date DATE ,
PRIMARY KEY (product_id)
);- 使用
INSERT语句可以向表中插入数据(行)。原则上,INSERT语句每次执行一行数据的插入。
-- INSERT 语句定义:
INSERT INTO <表名> (列1, 列2, 列3, ……) VALUES (值1, 值2, 值3, ……);
-- 插入一条数据的示例:
INSERT INTO ProductIns (product_id, product_name, product_type, sale_price, purchase_price, regist_date)
VALUES ('0001', 'T恤衫', '衣服', 1000, 500, '2009-09-20');将列名和值用逗号隔开,分别括在(半角)括号()内,这种形式称为清单。
对表中所有列进行
INSERT操作时可以省略表名后的列清单。
-- 对表进行全列 INSERT 时,可以省略表名后的列清单
-- 以下示例效果同上:
INSERT INTO ProductIns VALUES ('0001', 'T恤衫', '衣服', 1000, 500, '2009-09-20');- 插入 NULL 时需要在
VALUES子句的值清单中写入 NULL。 - 可以为表中的列设定默认值(初始值),默认值可以通过在
CREATE TABLE语句中为列设置DEFAULT约束来设定。
-- 参照 ProductIns 表的创建,DEFAULT 约束设定默认值:
CREATE TABLE ProductIns
(product_id CHAR(4) NOT NULL,
……
sale_price INTEGER DEFAULT 0, -- 销售单价初始值默认为 0;
……
PRIMARY KEY (product_id));- 插入默认值可以通过两种方式实现,即在
INSERT语句的 VALUES子句中指定DEFAULT关键字(显式方法),或省略列清单(隐式方法)。 (显式方法插入默认值最好)
-- 显式方法插入默认值:
INSERT INTO ProductIns (product_id, product_name, product_type, sale_price, purchase_price, regist_date)
VALUES ('0007', '擦菜板', '厨房用具', DEFAULT, 790, '2009-04-28');- 使用
INSERT…SELECT可以从其他表中复制数据。
-- 创建一个空白示例表:
-- 用来插入数据的商品复制表
CREATE TABLE ProductCopy
(product_id CHAR(4) NOT NULL,
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32) NOT NULL,
sale_price INTEGER ,
purchase_price INTEGER ,
regist_date DATE ,
PRIMARY KEY (product_id));
-- 将商品表中的数据复制到商品复制表中
INSERT INTO ProductCopy (product_id, product_name, product_type, sale_price, purchase_price, regist_date)
SELECT product_id, product_name, product_type, sale_price, purchase_price, regist_date
FROM Product;现在 ProductCopy 中插入了与 ProductIns 完全相同的八行数据,而原有的 ProductIns 表不会改变。
- 在
INSERT语句的SELECT语句中,可以使用WHERE子句或者GROUP BY子句等任何 SQL 语法(但使用ORDER BY子句并不会产生任何效果)。
-- 根据商品种类进行汇总的表 ;
CREATE TABLE ProductType
(
product_type VARCHAR(32) NOT NULL,
sum_sale_price INTEGER ,
sum_purchase_price INTEGER ,
PRIMARY KEY (product_type)
);
-- 插入其他表中数据合计值的 INSERT…SELECT 语句:
INSERT INTO ProductType (product_type, sum_sale_price, sum_purchase_price)
SELECT product_type, SUM(sale_price), SUM(purchase_price)
FROM Product
GROUP BY product_type;删除 DELETE
- 如果想将整个表全部删除,可以使用
DROP TABLE语句,如果只想删除表中全部数据,需使用DELETE语句。
-- 保留数据表,仅删除全部数据行的 DELETE 语句
DELETE FROM <表名>;
-- 例如:清空 Product 表
DELETE FROM Product;注意:DELETE语句的删除对象并不是表或者列,而是记录(行)。
搜索型 DELETE
- 如果想删除部分数据行,只需在
WHERE子句中书写对象数据的条件即可。通过WHERE子句指定删除对象的DELETE语句称为搜索型DELETE语句。
-- 删除部分数据行的搜索型 DELETE
DELETE FROM <表名>
WHERE <条件>;注意:与 SELECT 语句不同的是,DELETE 语句中不能使用 GROUP BY、HAVING 和 ORDER BY 三类子句,而只能使用 WHERE 子句 。
更新 UPDATE
- 使用 UPDATE语句可以更改(更新)表中的数据。
-- 改变表中数据的 UPDATE 语句
UPDATE <表名>
SET <列名> = <表达式>;搜索型 UPDATE
- 更新部分数据行时可以使用
WHERE来指定更新对象的条件。通过WHERE子句指定更新对象的UPDATE语句称为搜索型UPDATE语句。
-- 更新部分数据行的搜索型 UPDATE
UPDATE <表名>
SET <列名> = <表达式>
WHERE <条件>;
-- 示例:将商品种类为厨房用具的记录的销售单价更新为原来的 10 倍
UPDATE Product
SET sale_price = sale_price * 10
WHERE product_type = '厨房用具';UPDATE语句可以将列的值更新为 NULL。
-- 将商品编号为 0008 的数据(圆珠笔)的登记日期更新为 NULL
UPDATE Product
SET regist_date = NULL
WHERE product_id = '0008';注意:使用 UPDATE语句可以将值清空为 NULL(但只限于未设置 NOT NULL约束的列)。
- 同时更新多列时,可以在
UPDATE语句的SET子句中,使用逗号分隔更新对象的多个列。
-- 繁琐的 UPDATE 语句
UPDATE Product
SET sale_price = sale_price * 10
WHERE product_type = '厨房用具';
UPDATE Product
SET purchase_price = purchase_price / 2
WHERE product_type = '厨房用具';
-- 合并为一条 UPDATE语句
-- 使用逗号对列进行分隔排列
UPDATE Product
SET sale_price = sale_price * 10,
purchase_price = purchase_price / 2
WHERE product_type = '厨房用具';事务
这是一个全新的概念,我觉得蛮好理解的:
- 事务是需要在同一个处理单元中执行的一系列更新处理的集合。
通过使用事务,可以对数据库中的数据更新处理的提交和取消进行管理。
-- 将两条 SQL 语句在事务中执行:
START TRANSACTION
-- 将运动T恤的销售单价降低1000日元
UPDATE Product
SET sale_price = sale_price - 1000
WHERE product_name = '运动T恤';
-- 将T恤衫的销售单价上浮1000日元
UPDATE Product
SET sale_price = sale_price + 1000
WHERE product_name = 'T恤衫';
COMMIT- 事务处理的终止指令包括
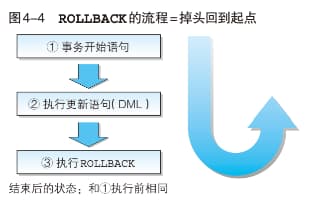
COMMIT(提交处理)和ROLLBACK(取消处理)两种。
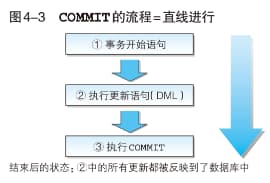
注意:特别是在执行 DELETE 语句的 COMMIT 时尤其要小心。
在这里,我引用一段作者对现代关系型数据库管理系统的描述:
实际上,几乎所有的数据库产品的事务都无需开始指令。这是因为大部分情况下,事务在数据库连接建立时就已经悄悄开始了,并不需要用户再明确发出开始指令。例如,使用 Oracle 时,数据库连接建立之后,第一条 SQL 语句执行的同时,事务就已经悄悄开始了。
例如,PostgreSQL的用户手册中有如下记述 :「PostgreSQL 中所有的SQL指令语句都在事务内执行。即使不执行
BEGIN,这些命令语句也会在执行时悄悄被括在BEGIN和COMMIT(如果成功的话)之间。」(《PostgreSQL 9.5.2 文档》“3-4 节 事务”)
- DBMS 的事务具有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)四种特性。通常将这四种特性的首字母结合起来,统称为 ACID 特性。